

OpenClaw:当 AI Agent 成为你的"操作系统"
引言:为什么 OpenClaw 值得关注?
如果你关注 AI 领域,肯定听说过 OpenClaw——这个在 2026 年初爆火的开源 AI Agent 框架,成为了 GitHub 历史上增长最快的项目。
但作为技术出身的产品经理,我更关心的是:它到底能解决什么实际问题?在生产环境中表现如何?未来的想象空间在哪?
我并非要做产品介绍,而是针对这段时间亲身实践的场景化分析 + 技术洞察 + 未来趋势判断。
一、OpenClaw 是什么?重新定义 AI Agent
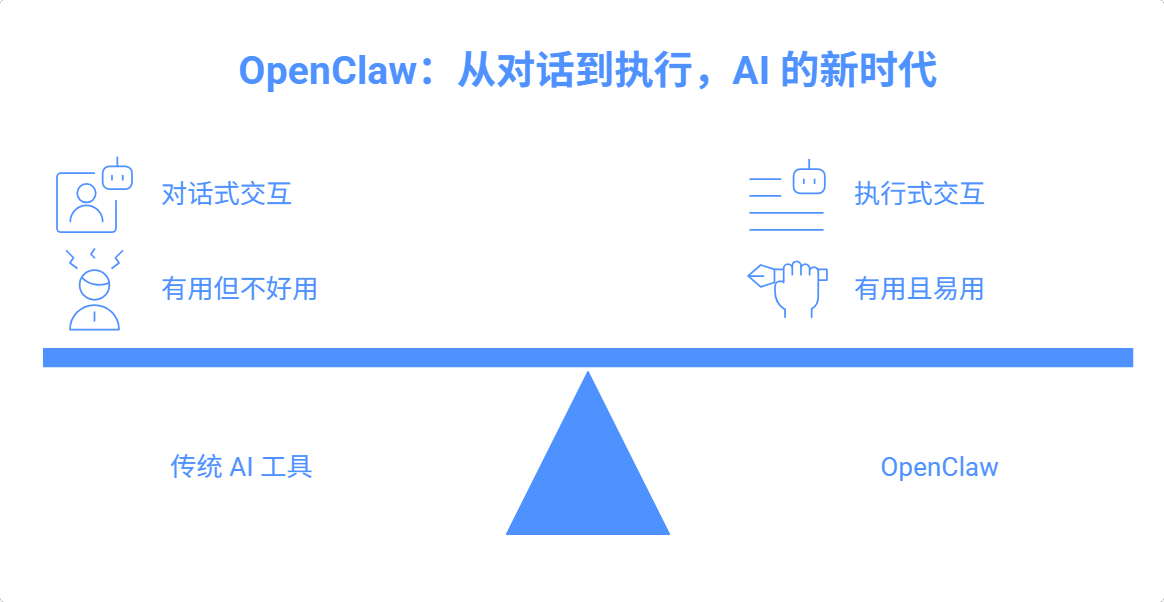
1.1 不是聊天机器人,是"操作系统"
传统 AI 工具(ChatGPT、豆包 等)是"对话式"的——你问,它答。但 OpenClaw 是 "执行式" 的——你告诉目标,它自己想办法完成。
举个例子:
传统 AI: "帮我查一下今天天气" → 你收到文字描述
OpenClaw: "每天早上 8 点给我推天气" → 它自动配置 cron 任务,每天准时推送,你什么都不用管
这就是 OpenClaw 的核心理念:AI 应该成为你的"操作系统",而不是"搜索引擎" 。
1.2 GitHub 历史上增长最快项目的秘密
OpenClaw 在 2026 年初爆火,成为 GitHub 历史上增长最快的开源项目(甚至超过了当年的 Vue.js)。为什么?
答案很简单:它解决了"AI 有用但不好用"的痛点。
有用: ChatGPT 能写代码、查资料、写文案
不好用: 你得打开浏览器 → 登录 → 输入 → 复制粘贴 → 手动执行
OpenClaw 的创新在于:把 AI 和现实世界连接起来。它不只是"懂你",而是能"为你做事"。
二、为什么定时任务是"杀手级特性"?
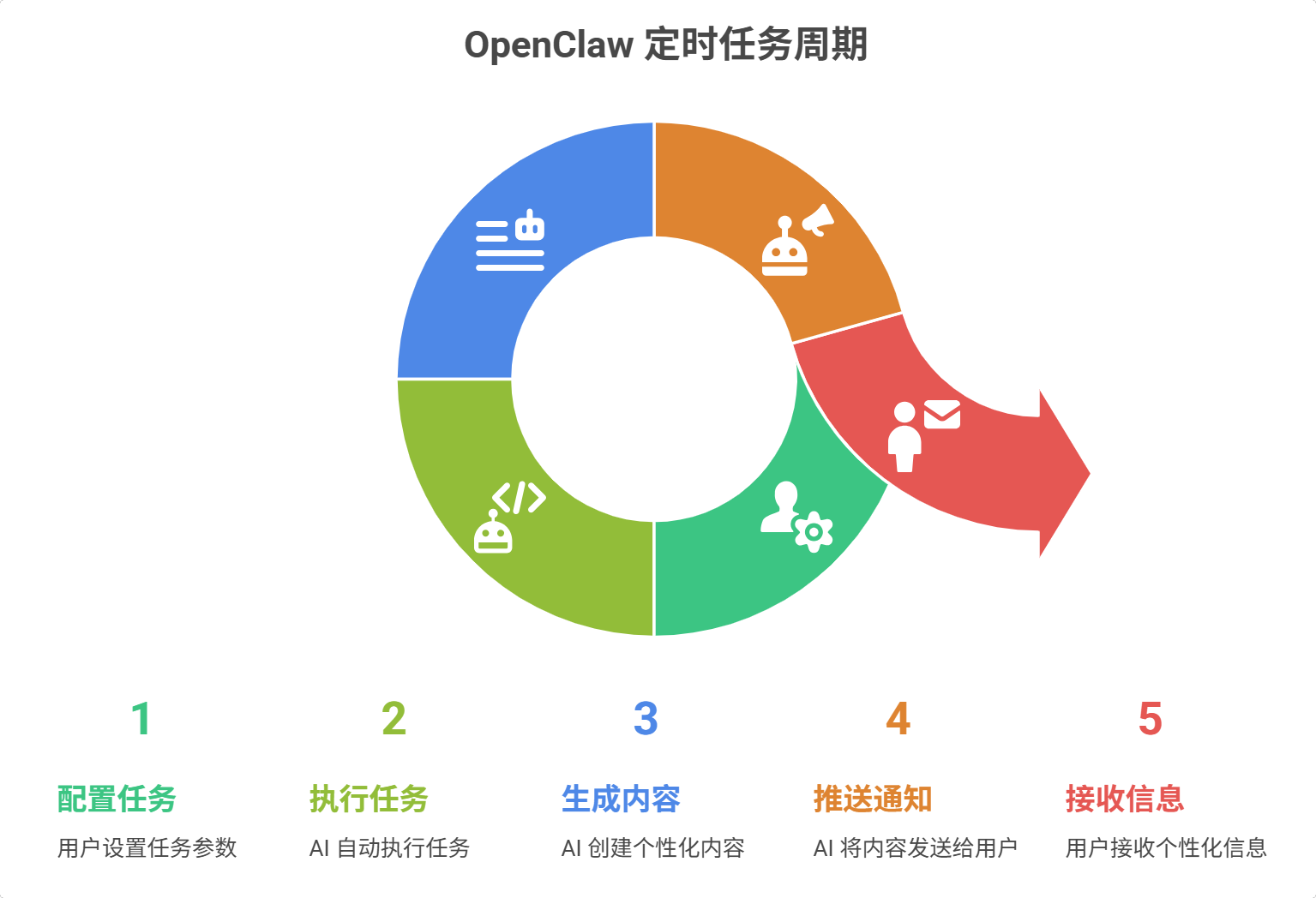
先说一个观察:大多数 AI 工具都在解决"怎么更好地对话",但 OpenClaw 解决的是"怎么让 AI 主动为你工作"。
定时任务就是最典型的例子。
传统模式下,你想查天气要打开 App、看新闻要刷新网站、监控服务器要登录后台。但 OpenClaw 的做法是:你告诉它一次,它永远记住,并且自动执行。
比如天气播报这个场景。我配置好之后,每天早上 8 点,它会自动:
调用 Open-Meteo API 查询天气
根据温度、天气状况生成个性化文案("今天有点冷,记得加件薄外套")
推送到 Telegram 群聊的专属话题
我完全不用管,它自己会做。
这听起来简单,但背后的产品逻辑很深刻:从"人找信息"到"信息找人" 。我每天早上打开 Telegram,就能看到我关心的内容(天气、新闻、技术动态),而不需要主动去查。
更关键的是,它能个性化过滤。比如我知道某个朋友喜欢国际政治,另一个朋友关注 AI 资讯,OpenClaw 可以给不同的人推不同的内容。
这是 AI Agent 区别于传统 AI 的核心能力:不只是"懂你",而是"为你做事"。
三、自动化部署:从"黑科技"到"生产力工具"
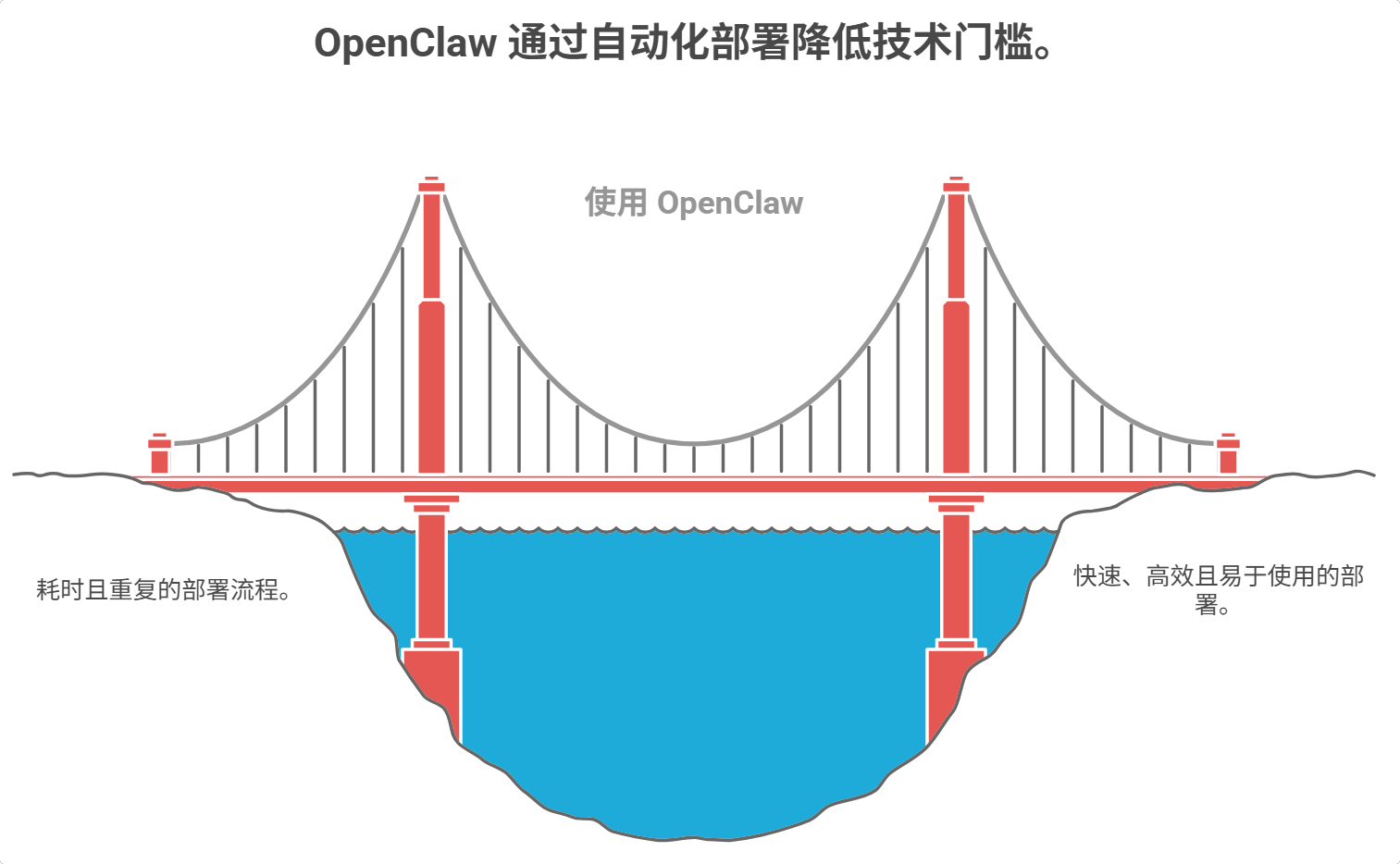
如果说定时任务是"主动服务",那自动化部署就是"降维打击"。
传统的部署流程是什么?看文档、配环境、装依赖、debug 报错、再配置、再报错……一个复杂项目可能要折腾半天甚至几天。
但 OpenClaw 的逻辑是:给我一个 GitHub 链接,剩下的我来搞定。
它会自动分析项目结构(前端是什么框架、后端用什么语言、需不需要数据库),然后自己查文档、配环境、装依赖、启动服务。遇到报错就自己 debug,解决不了才找你。
我测试过一个包含 React 前端 + Node.js 后端 + PostgreSQL 数据库 + Redis 缓存的项目,整个过程 30 分钟搞定,我唯一做的事就是把 GitHub 链接发给它。
这意味着什么?
对于非技术人员,他们可以部署任何开源项目,不需要懂 Docker、Kubernetes。对于技术人员,他们可以把时间花在更重要的事情上,而不是重复的部署工作。
但更深层的影响是:这改变了"技术门槛"的定义。
以前,"会用 Linux"是门槛;现在,"会描述需求"就够了。未来,可能连"描述需求"都不需要,AI 会自己推断你需要什么。
四、ClawHub:AI Agent 的"App Store"

OpenClaw 有一个插件生态叫 ClawHub,这让我想起 2008 年的 App Store。
当时,iPhone 已经很强大,但真正让它爆发的是 App Store——任何人都可以开发应用,用户可以按需下载。OpenClaw 的逻辑类似:核心框架提供基础能力,Skills 提供垂直场景的解决方案。
比如我现在常用的几个 Skills:
weather: 天气查询和推送(这个我已经配置成每天早上的例行任务)
github: 自动处理 Issues、PR、CI 流程(对于开源项目维护者非常有用)
1password: 安全读取密码和密钥(不需要明文存储敏感信息)
obsidian: 自动整理和检索笔记库(我有 1000+ 篇笔记,它能精准定位)
frontend-design: 生成高质量前端代码(这个让我这个后端出身的人也能快速做网页)
ClawHub 的价值不只是"功能多",而是"按需扩展"。
我不需要的功能就不装,不会像某些臃肿的软件一样,装了一堆我永远不会用的功能。而且,社区可以贡献 Skills,这意味着 OpenClaw 的能力会随着用户增长而增强。
这让我想起一个判断:未来的 AI Agent 竞争,不是比"谁更聪明",而是比"谁的生态更繁荣"。
五、跨平台操作:一个接口,管理所有环境
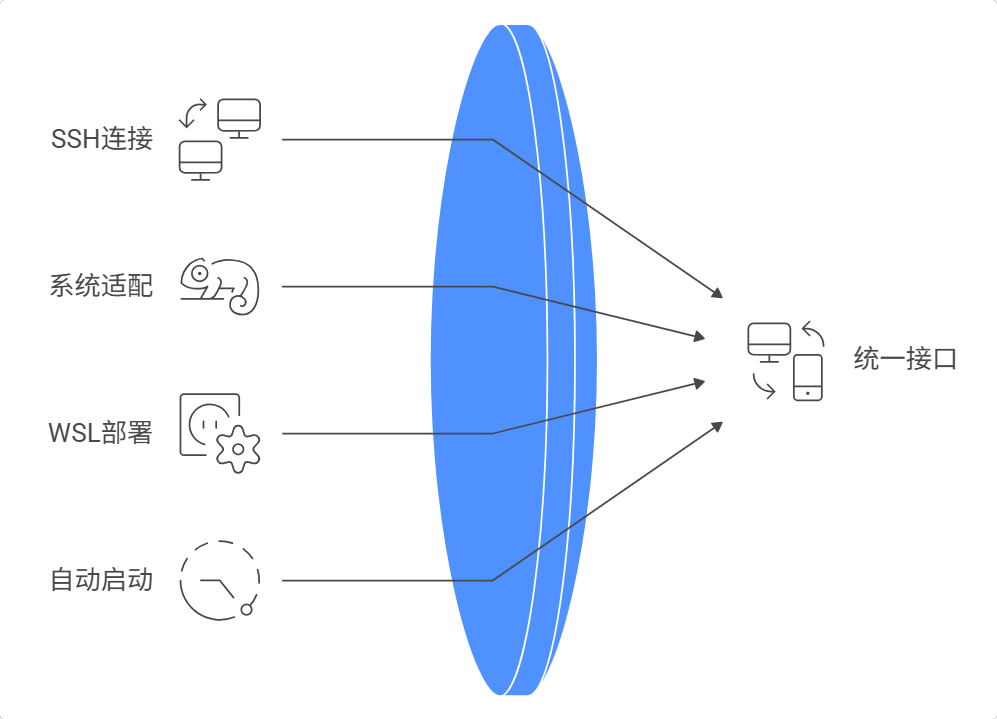
这个场景可能不太显眼,但在实际工作中非常有用,尤其是现在很多人玩nas,都有自己的家庭存储和服务器,多台服务器或虚拟机之间的运维工作有时还挺让人头疼。
比如我有多台服务器:Linux、Mac、Windows,以前要管理这些服务器得用不同的工具、记不同的命令。但 OpenClaw 可以通过 SSH 连接所有服务器,并且自动适配不同系统。
举个例子,我有一台 Windows 服务器想装 OpenClaw,但官方只支持 Linux/Mac,我自己手动安装总会遇到奇奇怪怪的问题,即便我咨询了AI得到各种解决办法,依旧无法部署成功。某一天我突然想到为什么不借助openclaw来做这件事呢,于是我直接告诉了一台linux主机上的openclaw:"帮我在 Windows 上部署 OpenClaw。"
它自己:
通过ssh连接 Windows 服务器(ssh安装方式也是openclaw告诉我的,当然这一步需要我提前手动执行)
查阅文档,找到 WSL(Windows Subsystem for Linux)方案
安装 WSL + Ubuntu
在 WSL 里部署 OpenClaw
配置自动启动
全程我没碰过那台 Windows 服务器,除了提前安装ssh工具。
这背后的技术不复杂(SSH + 文档检索 + 命令执行),但产品价值在于"统一接口" 。我不需要关心底层是 Linux 还是 Windows,只需要用自然语言描述需求,OpenClaw 会自己找方案。
对于运维团队来说,这意味着:一个人可以管理更多的服务器,因为重复性的工作都自动化了。
六、单向文档同步:在"能力"和"安全"之间找平衡
给 AI 足够的能力,但要限制它的破坏力。
我有大量的技术文档、项目资料、个人笔记(Obsidian),希望 OpenClaw 能帮我检索和管理。但我担心一个问题:如果 AI 误删了我的文件怎么办?
所以我想到了一个方案:单向同步。
源数据文档 → 同步到 OpenClaw 服务器,OpenClaw 可以读取并修改,但修改的内容并不会同步到其他地方,避免影响源数据。这样,它可以理解我的知识库、帮我检索信息、回答问题,但永远不会因为误删文件导致文件丢失,可以允许它乱做,但不能直接影响你的数据。
这听起来像是一个"防御性设计",但实际上反映了 AI Agent 的一个核心挑战:如何在不失控的前提下,给 AI 足够的自主权?
我认为未来会有更多类似的"安全边界"设计:
可以读取代码,但不能直接提交到生产分支
可以查看数据库,但不能执行 DELETE 操作
可以发送邮件,但不能发给重要客户
AI 的能力越强,安全边界的设计就越重要。
七、浏览器自动化:Web 测试的"降维打击"
最后这个场景,是我认为最被低估的能力。
传统的 Web 测试要么靠人工(慢、容易遗漏),要么靠脚本(维护成本高)。但 OpenClaw 可以像真人一样操作浏览器,并且自动生成测试用例。
比如我要测试一个电商网站:
功能测试:自动注册、登录、浏览商品、加入购物车、提交订单
安全测试:尝试 SQL 注入、XSS 攻击、检测敏感信息泄露
兼容性测试:检查不同浏览器、不同分辨率下的表现
它会自动截图、录屏、生成测试报告,标注问题的严重等级。
这对于小团队来说是"降维打击" 。以前需要专门招测试工程师,现在 AI 可以完成大部分工作。对于大团队,它可以作为自动化测试的补充,覆盖那些容易被忽略的边缘场景。
更深层的影响是:这改变了"质量保障"的成本结构。 以前测试是"成本中心",现在通过自动化,测试可以做到既全面又高效。
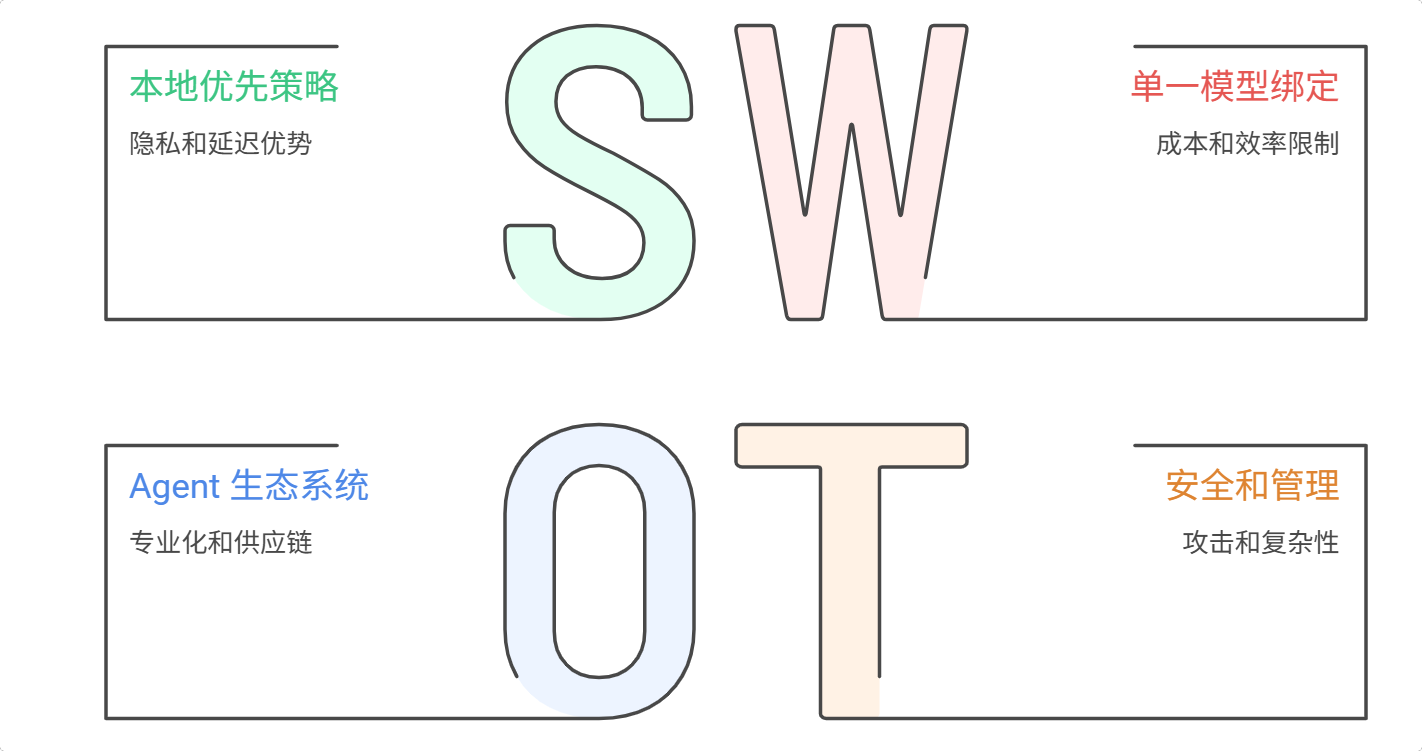
八、OpenClaw 的"护城河":本地优先、多平台、模型无关
说完场景,聊聊 OpenClaw 的核心优势。我认为它有三个"护城河",也是区别于其他 AI 工具的关键。
1. 本地优先(Local-First)
所有数据都在你自己的服务器上:对话记录、文件、密钥。这意味着:
隐私有保障:数据不上传到第三方
离线可用:配合本地模型,断网也能工作
完全控制:你可以随时查看、修改、删除所有数据
对比云端 AI 服务(ChatGPT、Claude 等),这是一个巨大的差异。
对于隐私敏感的场景(企业内部、个人敏感信息),本地优先是刚需。
2. 多平台统一入口
OpenClaw 支持 Telegram、WhatsApp、Slack、Discord、Signal、iMessage 等十几个平台。
这意味着:你用熟悉的工具(比如 Telegram)和它聊天,但它可以帮你操作其他平台(发邮件、管理 Slack、处理 GitHub Issues)。
这是一个"统一入口"的概念——不需要在不同 App 之间切换,一个 Agent 搞定所有事。
3. 模型无关(Model-Agnostic)
OpenClaw 不绑定任何 AI 厂商。你可以用:
云端模型:GPT-4、Claude、Gemini、DeepSeek
本地模型:Ollama、LocalAI 等开源方案
混合部署:简单任务用本地模型(免费),复杂任务用云端模型(强大)
这给了用户极大的灵活性。
不过需要提醒的是,openclaw对token的消耗极大,建议想办法白嫖或者开通coding plan去跑比较合适。
九、现实很骨感:OpenClaw 的 3 个核心挑战
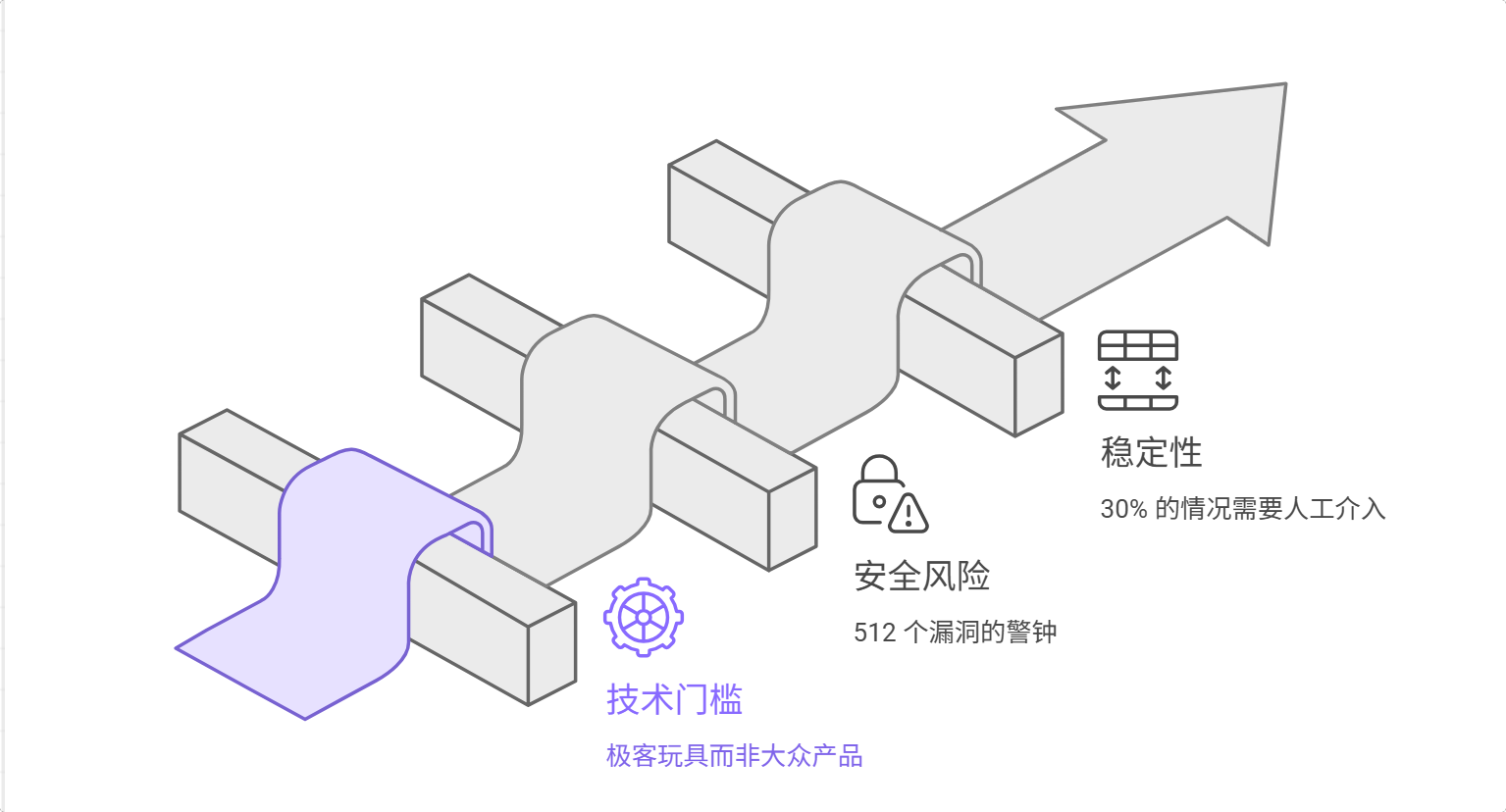
说了这么多好处,也得聊聊现实问题。OpenClaw 不是银弹,它有几个明显的短板。
挑战 1:技术门槛——"极客玩具"而非"大众产品"
OpenClaw 不是开箱即用的。你需要:
懂 Linux 基础(文件系统、权限、服务管理)
会配置环境变量、API 密钥
理解 Agent 的工作原理(prompt、工具调用、上下文管理)
这就像早期的 Linux:强大,但只适合技术人员。
我认为,OpenClaw 要普及,需要做到"零配置":
一键安装(类似 Docker Desktop)
图形化管理界面(不全是命令行)
预设模板(常见场景开箱即用)
我预测,6 个月内会出现"OpenClaw 各类服务",降低使用门槛。
挑战 2:安全风险——"512 个漏洞"的警钟
2026 年 1 月的安全审计发现,OpenClaw(当时叫 Clawdbot)存在 512 个漏洞,其中 8 个严重。
主要风险:
权限提升: Agent 可能获得超出预期的系统权限
数据泄露: 配置不当可能导致敏感信息暴露
命令注入: 恶意 prompt 可能触发危险操作
我的做法是:像对待"有 root 权限的实习生"一样对待 OpenClaw。
给足够的权限完成工作,但要有监督和限制:
只在内网部署,不暴露在公网
定期更新到最新版本
限制敏感权限(银行账号、生产数据库)
启用审计日志,监控所有操作
但说实话,这对普通用户来说太复杂了。OpenClaw 需要内置更完善的安全机制。
挑战 3:稳定性——30% 的情况需要人工介入
在实际使用中,大约 20% 的情况需要人工介入。
常见问题:
模型 API 限流: 高频调用触发速率限制
理解偏差: 复杂指令被误解
幻觉输出: 模型生成不实信息
工具失败: 外部 API 故障或网络问题
这意味着:OpenClaw 还不能完全"放手"。
对于关键任务,我还是会人工审核。对于非关键任务,我会设计降级方案(比如定时任务失败后,用简单的脚本兜底)。
现状判断:技术已可用,但距离"生产级稳定性"还有 1-2 年的差距。
十、未来趋势判断:AI Agent 的 5 个关键方向
基于对 OpenClaw 的实践和对 AI 行业的观察,我认为未来 2-3 年,AI Agent 会在以下 5 个方向发生深刻变化。
趋势 1:从"通用 Agent"到"Agent 生态"
现在的 OpenClaw 是一个"万能助手",什么都能做,但可能什么都不够专业。未来的趋势是专业化分工。
我预测会出现这样的架构:
通用 Agent: 负责理解需求、分配任务
专业 Agent: 定时任务专员、搜索专员、代码专员、数据分析专员等
协调机制: Agent 之间通信、协作、冲突解决
类比:这就像从"全栈工程师"到"工程团队"的演进。
更关键的是,Agent 之间会形成"供应链" 。比如一个 Agent 负责抓取数据,另一个 Agent 负责分析,第三个 Agent 负责生成报告,第四个 Agent 负责推送。
这会催生一个新的职业:Agent 架构师。 他们的工作是设计 Agent 之间的协作流程,优化效率。
趋势 2:从"被动响应"到"主动预测"
这是我认为最关键的突破点。
现在的 OpenClaw 还是"你让它做,它才做"。但未来的 AI Agent 应该在你开口之前就知道你需要什么。
技术上,这需要:
行为建模: 学习你的行为模式(比如每天早上查天气、每周五下午总结工作)
上下文理解: 知道你当前在做什么、接下来可能需要什么
资源预测: 预判可能出现的问题(比如服务器快满了、会议要迟到了)
也许1 年内会出现"主动式 AI Agent"的产品,它会主动告诉你:"我注意到你明天有重要会议,已经帮你查了交通状况,建议你提前 20 分钟出发。"
这会彻底改变人和 AI 的关系:从"工具"到"伙伴"。
趋势 3:从"云端优先"到"边缘智能"
OpenClaw 的"本地优先"策略是对的,但我认为会更进一步:AI Agent 会运行在边缘设备上。
为什么?
隐私: 敏感数据不出本地设备
延迟: 边缘计算更快响应
成本: 不需要持续调用云端 API
未来 "手机原生 AI Agent"会开始普及,它运行在你的手机上,能访问你的通讯录、日历、文件,但所有数据都不离开手机。
这会催生一个新的硬件市场:AI Agent 专用芯片(类似苹果的 Neural Engine,但更强)。
趋势 4:从"单一模型"到"模型路由"
现在的 AI Agent 通常绑定一个模型(比如 GPT-4)。但未来的趋势是动态选择模型。
简单任务用便宜模型(比如 Haiku),复杂任务用强大模型(比如 Opus),特殊任务用专用模型(比如代码生成用 CodeLlama)。
这会大幅降低成本。 我估计,通过智能路由,AI Agent 的调用成本可以降低 50-70%。
OpenClaw 未来一定会支持"模型路由"功能,根据任务复杂度自动选择最合适的模型。
趋势 5:从"个人工具"到"组织基础设施"
现在 OpenClaw 主要是个人使用,但我认为企业级 AI Agent 会成为新的基础设施。
想象一下:
每个员工都有 AI 助手:自动处理邮件、安排会议、生成报告
部门级 Agent:销售 Agent、客服 Agent、运维 Agent
组织级 Agent:跨部门协调、资源分配、决策支持
这会改变组织的运作方式。 以前需要 10 个人的团队,未来可能只需要 3 个人 + 7 个 Agent。
2027 年估计会有 30% 的企业部署"AI Agent 基础设施",类似于现在部署 CRM、ERP 一样普遍。
但这也带来挑战:
安全风险:如果 Agent 被攻击,可能影响整个组织
管理复杂度:如何管理成百上千个 Agent?
伦理问题:Agent 的决策失误,责任在谁?
总结一下我的核心判断:
Agent 生态会取代单一 Agent,专业化分工是趋势
主动预测是下一个突破点,AI 会比你自己更懂你的需求
边缘智能会崛起,隐私和延迟是驱动力
模型路由会降低成本,让 AI Agent 更普及
企业级部署会成为主流,AI Agent 会像 CRM 一样成为基础设施
OpenClaw 现在处于"早期采用者"阶段,但 2 年后,它可能会成为"标配"。
十一、适合你吗?一个简单的判断标准
最后,给潜在用户一个实用的建议。
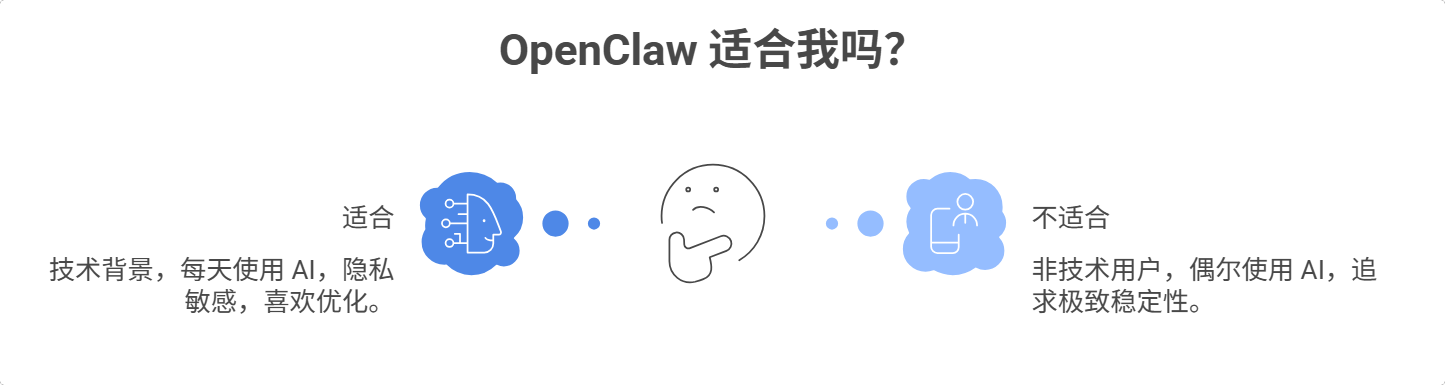
如果你符合以下特征,OpenClaw 值得一试:
技术背景(至少懂 Linux 基础)
每天都要用 AI 辅助工作
隐私敏感(数据不能上云)
喜欢折腾、愿意投入时间优化
如果你是以下情况,建议再等等:
非技术用户
偶尔使用 AI(用 ChatGPT 就够了)
追求极致稳定性
我的建议是:从低风险场景开始。
先试试定时任务(天气播报、新闻推送),建立信任后再扩展到自动化部署、浏览器测试等高风险场景。不要一上来就给它生产数据库的权限,先让它管测试环境。
记住:OpenClaw 是"实习生",不是"资深工程师"。给它足够的权限,但要监督它的工作。
结语:AI Agent 时代的"Linux 时刻"
写到这儿,我想起 2005 年的 Linux。
当时,Linux 已经很强大,但只有极客在用。普通人觉得它复杂、不稳定、没有商业支持。但 20 年后,Linux 成了互联网的基础设施——服务器、手机、路由器、智能设备,无处不在。
OpenClaw 现在就像 2005 年的 Linux。
它不完美,有技术门槛,有安全风险,稳定性还不够。但它代表了一个方向:AI 不应该只是"对话",而应该"行动"。
我判断,2-3 年后,AI Agent 会成为像 CRM、ERP 一样的基础设施。每个技术人员都会有一个 AI 助手,每个团队都会有 Agent 生态。
现在探索 OpenClaw,就是在为未来做准备。
最后分享一个洞察:
很多人问我,OpenClaw 和 ChatGPT 的区别是什么?我的回答是:ChatGPT 是"咨询顾问",OpenClaw 是"执行团队"。
前者给你建议,后者帮你干活。
在 AI 时代,"执行力"比"智商"更重要。











